



RAID 6 - Fault Tolerance w/ Dual Parity (Minimum 4 HDD's Required)
- SKU: 7956959
- Manufacturer: AVADIRECT
- MPN: RAID-6
- Availability: CONTACT US
|
What Is RAID? As it was originally proposed, the acronym RAID stood for Redundant Array of Inexpensive Disks. However, it has since come to be known as Redundant Array of Independent Disks. RAID was originally described in the paper "A Case for Redundant Arrays of Inexpensive Disks (RAID)" written by three University of California Berkeley researchers: David Patterson, Garth Gibson, and Randy Katz. The concept was presented at the 1988 conference of the ACM Special Interest Group on Management of Data (SIGMOD). In the original Berkeley paper there were five RAID levels (1-5). RAID-6 was added later as an enhancement for RAID-5. In time other levels have been implemented by various companies using the concepts described in the original proposal. These include RAID-0 (striping without redundancy), and multilevel RAID (striping across RAID arrays), and others variants. The Levels of RAID
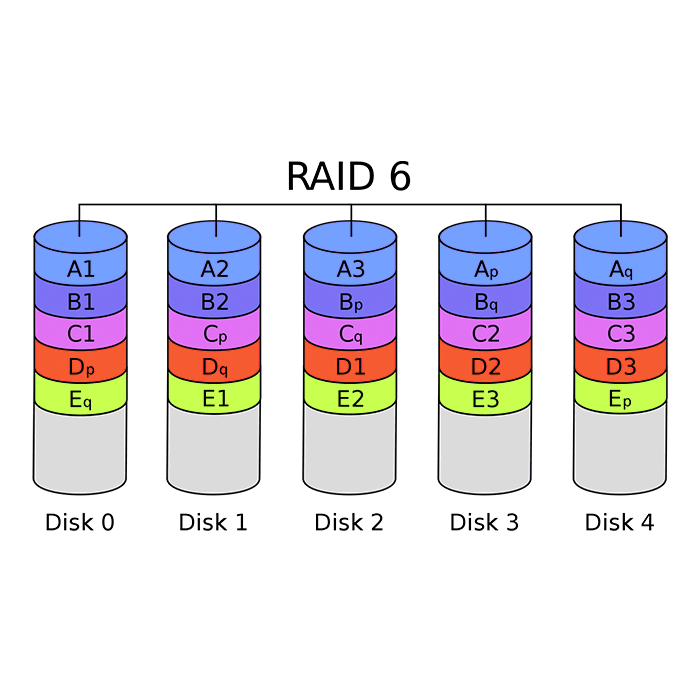
RAID 6 RAID 6 is essentially an extension of RAID level 5 which allows for additional fault tolerance by using a second independent distributed parity scheme (dual parity) Data is striped on a block level across a set of drives, just like in RAID 5, and a second set of parity is calculated and written across all the drives; RAID 6 provides for an extremely high data fault tolerance and can sustain multiple simultaneous drive failures RAID 6 protects against multiple bad block failures while non-degraded RAID 6 prodects against a single bad block failure while operating in a degraded mode Perfect solution for mission critical applications |